CAPSTONE • TORONTO METROPOLITAN UNIVERSITY
DATA ANALYSIS • MACHINE LEARNING • 2026
ROLE
Researcher & Data Analyst TMU Student
Predictive
Modelling of
Cervical Cancer
Risk Factors
DATASET
REPORT
01 - ABSTRACT
PYTHON
XG BOOST
DATA MINING
Cervical cancer kills an estimated 94% of its victims in low- and middle-income countries — not because it's undetectable, but because screening access is limited. This project asked: can machine learning models trained on routinely collected patient history data meaningfully identify who is at risk, before they reach a clinic?
WHY CERVICAL CANCER?
I chose cervical cancer as the focus of my data analysis project because it is deeply personal to me. My mom passed away from cervical cancer, and that experience shaped my interest in understanding the disease beyond a clinical perspective. Through this project, I wanted to explore how data can be used to identify risk factors, improve early detection, and ultimately contribute to better outcomes. It reflects both my analytical skill set and my motivation to apply data-driven insights to meaningful, real-world health challenges.
858
Patients
6.41%
Positive Cases
27
Features Used
5
Models Trained
02 - METHODOLOGY
How it was built
01
03
04
05
Data Preprocessing
Feature Importance
Stability & Analysis
Standardized missing value encodings across 36 variables. Removed features with >90% missingness. Excluded post-screening diagnostic columns (Hinselmann, Schiller, Citology, Dx variants) to eliminate information leakage. Final feature set: 27 predictors.
02
Model Selection
Selected 5 models spanning interpretability vs. performance: unweighted logistic regression (baseline), class-weighted logistic regression, decision tree (max depth=5), balanced random forest, and class-weighted XGBoost.
Training & Evaluation
75/25 stratified train-test split to preserve positive class ratio. Evaluated on accuracy, precision, recall, F1, and ROC-AUC. Recall was the primary metric — missing a true positive in a screening context is the most ethically costly error.
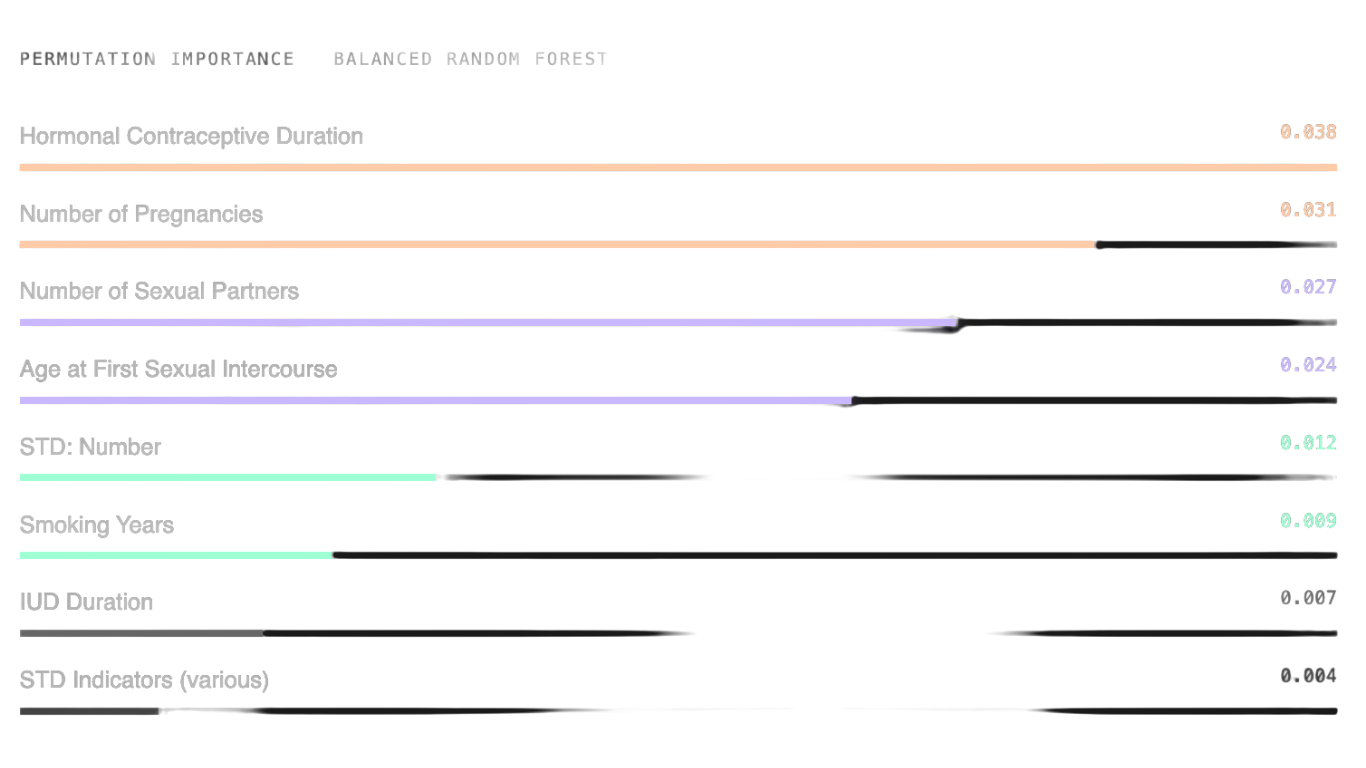
Permutation importance computed on balanced random forest (highest ROC-AUC). Top predictors: hormonal contraceptive duration, number of pregnancies, number of sexual partners, and age at first sexual intercourse.
Stratified cross-validation and repeated train-test splits assessed robustness. Class-weighted logistic regression showed highest mean recall (0.327). Random forest had highest mean ROC-AUC (0.671).
03 - RESULTS
Model Performance
MODEL
ACCURACY
0.9349
PRECISION
0.0000
RECALL
0.0000
F1
0.0000
ROC-AUC
0.6542
Logistic Regression (Class-Weighted)
BEST RECALL
0.7442
0.1273
0.5000
0.2029
0.6624
Decision Tree (max depth = 5)
0.9116
0.0000
0.0000
0.0000
0.4534
Random Forest (Balanced)
BEST ROC-AUC
0.9349
0.5000
0.0714
0.1250
0.6943
XGBoost (Class-Weighted)
0.8558
0.0952
0.1429
0.1143
0.5437
Primary evaluation metrics. Accuracy alone is misleading under severe class imbalance.
Logistic Regression (Unweighted)
Class-Weighted Logistic Regression
Highest recall on test set (0.50) and highest mean recall in cross-validation (0.327). Detects the most true positives — aligned with the goal of not missing high-risk patients.
BEST FOR SCREENING
Balanced Random Forest
Highest ROC-AUC (0.6953 on test, 0.671 mean). Best for ranking patients by risk when follow-up resources are limited. Feature importance via permutation analysis.
BEST DISCRIMINATION
Unweighted Models
LR (unweighted) and Decision Tree both achieved 0 recall despite high accuracy. Classic class-imbalance failure — high accuracy, zero clinical utility.
BASELINE TRAP
04 - FEATURE IMPORTANCE
What actually predicts risk
Permutation importance was computed on the balanced random forest — the model with the highest ROC-AUC. Each feature was shuffled in isolation; the drop in performance measures how much the model relied on it.
Reproductive and sexual history variables dominated. STD indicators were surprisingly weak predictors — consistent with prior literature, likely due to systematic underreporting of sensitive items.
04 - ETHICS & LIMITATIONS
What the model can’t do
Extreme Class Imbalance
Only 55 positive cases in 858. Recall and F1 scores swing significantly depending on which positives land in training vs. test. The models are not yet reliable enough for standalone clinical deployment.
LIMITATION
LIMITATION
Missing & Self-Reported Data
Several key predictors (STD subtypes, sexual history) have substantial missingness — partly because they are sensitive and underreported. This directly weakens the predictors the model most needs.
ETHICS
False Negatives > False Positives
A missed biopsy-positive case means a delayed diagnosis and potentially worse outcomes. The evaluation framework was deliberately oriented around sensitivity for this reason — accuracy is not the right metric here.
ETHICS
Decision-Support, Not Diagnosis
These models should only ever be used as risk-flagging tools with human clinical oversight. They must not be applied outside the population they were validated on, and thresholds must be documented and monitored.
05 - STACK & ACCESS
Tools & Resources
PYTHON
PANDAS
SCIKIT-LEARN
XGBOOST
JUPYTER NOTEBOOK
UCI ML REPOSITORY